This post was co-written by Ashish Prabhu, Stephen Johnston, and Colin Ingarfield at Morningstar and Don Drake, at AWS.
With “Empowering Financier Success” as the core slogan, Morningstar focuses on offering our financiers and consultants with the tools and info they require to make educated financial investment choices.
In this post, Morningstar’s Data Lake Group Leads go over how they used tag-based gain access to control in their information lake with AWS Lake Development and allowed comparable controls in Amazon Redshift
Business difficulty
At Morningstar, we constructed an information lake service that permits our customers to quickly consume information, make it available through the AWS Glue Information Brochure, and grant access to customers to query the information through Amazon Athena In this service, we were needed to make sure that the customers might just query the information to which they had specific gain access to. To implement our gain access to consents, we selected Lake Development tag-based gain access to control (TBAC). TBAC assists us classify the information into a basic, broad level or a complex, more granular level utilizing tags and after that grant customers access to those tags based upon what group of information they require. Tag-based privileges permit us to have a versatile and workable privileges system that resolves our complex privileges circumstances.
Nevertheless, our customers pressed us for much better question efficiency and improved analytical abilities. We understood we required an information storage facility to deal with all of these customer requirements, so we assessed Amazon Redshift. Amazon Redshift supplies us with functions that we might utilize to deal with our customers and allow their analytical requirements:
- Much better efficiency for customers’ analytical requirements
- Capability to tune question efficiency with user-specified sort secrets and circulation secrets
- Capability to have various representations of the exact same information through views and emerged views
- Constant question efficiency despite concurrency
Numerous brand-new Amazon Redshift includes assisted resolve and scale our analytical question requirements, particularly Amazon Redshift Serverless and Amazon Redshift information sharing.
Due To The Fact That our Lake Formation-enforced information lake is a main information repository for all our information, it makes good sense for us to stream the information consents from the information lake into Amazon Redshift. We make use of AWS Identity and Gain Access To Management (IAM) authentication and wish to centralize the governance of consents based upon IAM functions and groups. For each AWS Glue database and table, we have a matching Amazon Redshift schema and table. Our objective was to make sure clients who have access to AWS Glue tables through Lake Development likewise have access to the matching tables in Amazon Redshift.
Nevertheless, we dealt with an issue with user-based privileges as we transferred to Amazon Redshift.
The privileges issue
Although we included Amazon Redshift as part of our total service, the privilege requirements and difficulties that featured it stayed the exact same for our users taking in through Lake Development. At the exact same time, we needed to discover a method to execute privileges in our Amazon Redshift information storage facility with the exact same set of tags that we had actually currently specified in Lake Development. Amazon Redshift supports resource-based privileges however does not support tag-based privileges. The difficulty we needed to conquer was how to map our existing tag-based privileges in Lake Development to the resource-based privileges in Amazon Redshift.
The information in the AWS Glue Information Brochure required to be likewise filled in the Amazon Redshift information storage facility native tables. This was needed so that the users get a familiar list of schema and tables that they are accustomed to seeing in the Information Brochure when accessing through Athena. By doing this, our existing information lake customers might quickly shift to Amazon Redshift.
The following diagram highlights the structure of the AWS Glue Information Brochure mapped 1:1 with the structure of our Amazon Redshift information storage facility.

We wished to make use of the ontology of tags in Lake Development to likewise be utilized on the datasets in Amazon Redshift so that customers might be given access to the exact same datasets in both locations. This allowed us to have a single privilege policy source API that would approve proper access to both our Amazon Redshift tables in addition to the matching Lake Development tables based upon the Lake Development tag-based policies.
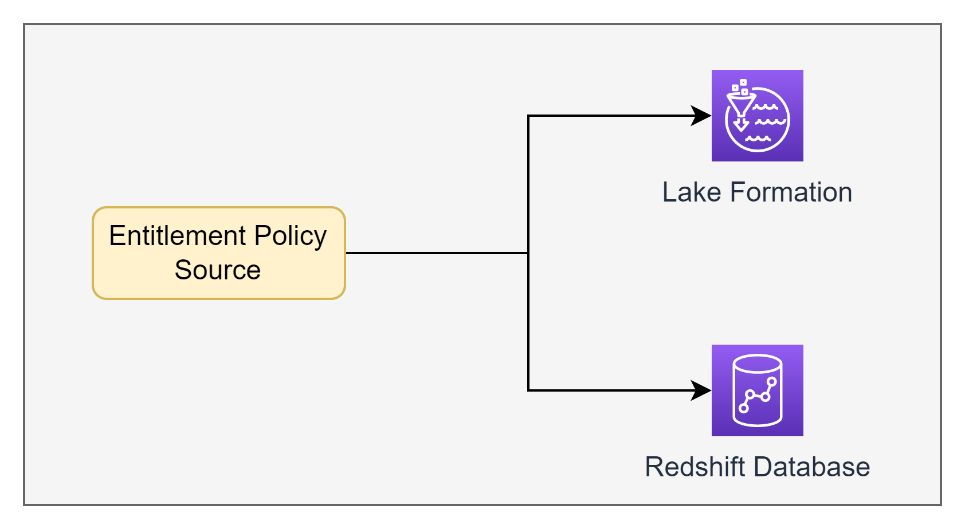
To resolve this issue, we required to construct our own service to transform the tag-based policies in Lake Development into grants and withdraws in the resource-based privileges in Amazon Redshift.
Service introduction
To resolve this inequality, we wished to integrate our Lake Development tag ontology and categories to the Amazon Redshift approval design. To do this, we map Lake Development tags and grants to Amazon Redshift grants with the following actions:
- Map all the resources (databases, schemas, tables, and more) in Lake Development that are tagged to their comparable Amazon Redshift tables.
- Equate each policy in Lake Development on a tag expression to a set of Amazon Redshift table grants and withdraws.
The net outcome is that when there is a tag or policy modification in Lake Development, a matching set of grants or revokes are made to the comparable Amazon Redshift tables to keep our privileges in sync.
Map all tagged resources in Lake Development to Amazon Redshift equivalents
The tag-based gain access to control of Lake Development enabled us to use numerous tags on a single resource (database and table) in the AWS Glue Information Brochure. If imagined in a mapping kind, the resource tagging can be shown as how numerous tags on a single table would be flattened into specific privileges on Amazon Redshift tables.
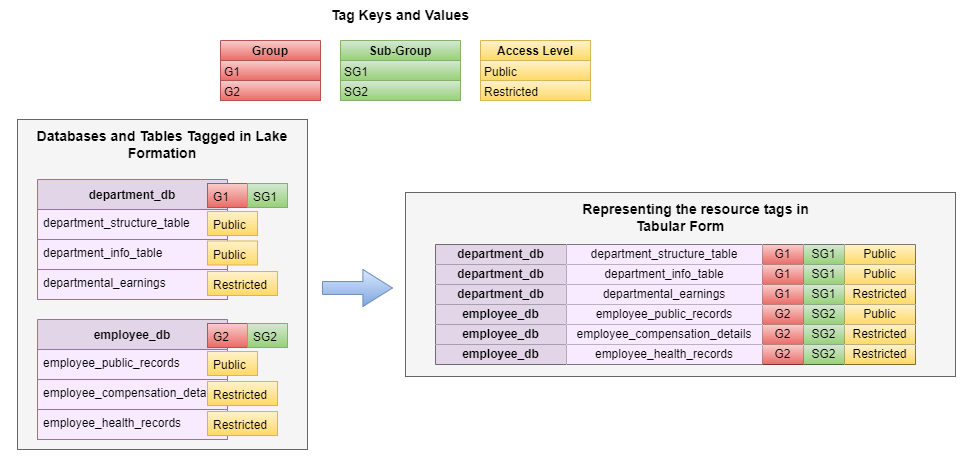
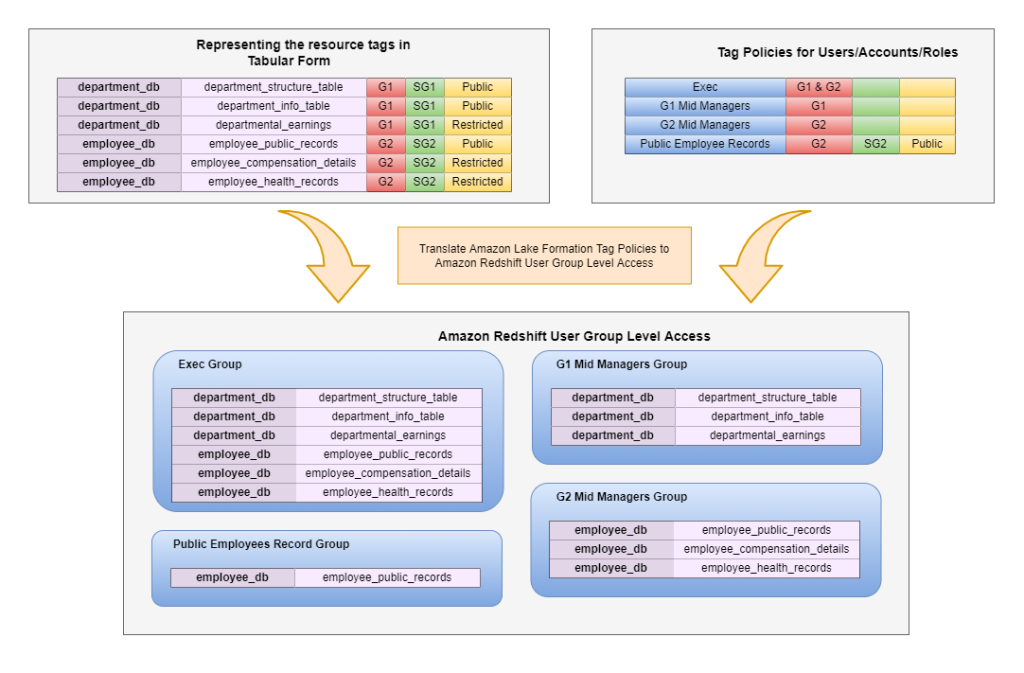
Equate tags to Amazon Redshift grants and withdraws
To make it possible for the migration of the tag-based policy implemented in Lake Development, the consents can be transformed into basic grants and withdraws that can be done on a per-group level.
There are 2 essential parts to a tag policy: the principal_id and the tag expression (for instance, “Acess Level”=”Public”). Presuming that we have an Amazon Redshift database group for each principal_id, then the resources that represent the tag expression can be permissioned appropriately. We intend on moving from database groups to database functions in a future application.
The service application
The application of this service led us to establish 2 parts:
- The mapper service
- The Amazon Redshift information setup
The mapper service can be considered a translation service. As the name recommends, it has the core service reasoning to map the tag and policy info into resource-based grants and withdraws in Amazon Redshift. It requires to imitate the habits of Lake Development when managing the tag policy translation.
To do this translation, the mapper requires to comprehend and save the metadata at 2 levels:
- Comprehending what resource in Amazon Redshift is to be tagged with what worth
- Tracking the grants and withdraws currently carried out so they can be upgraded with modifications in the policy
To do this, we produced a config schema in our Amazon Redshift cluster, which presently shops all the setups.
As part of our application, we save the mapped (equated) info in Amazon Redshift. This permits us to incrementally upgrade table grants as Lake Development tags or policies altered. The following diagram highlights this schema.

Company effect and worth
The service we created has actually produced crucial service effects and worths out of the present application and permits us higher versatility in the future.
It permits us to get the information to our users much faster with the tag policies used in Lake Development and equated straight to consents in Amazon Redshift with instant impact. It likewise permits us to have consistency in consents used in both Lake Development and Amazon Redshift, based upon the efficient consents originated from tag policies. And all this takes place through a single source that grants and withdraws consents throughout the board, rather of handling them independently.
If we equate this into business effect and service worth that we produce, the service enhances the time to market of our information, however at the exact same time supplies constant privileges throughout the business-driven classifications that we specify as tags.
The service likewise opens options to include more effect as our item scales both horizontally and vertically. There are prospective options we might execute in regards to automation, users self-servicing their consents, auditing, control panels, and more. As our service scales, we anticipate to make the most of these abilities.
Conclusion
In this post, we shared how Morningstar used tag-based gain access to control in our information lake with Lake Development and allowed comparable controls in Amazon Redshift. We established 2 parts that deal with mapping of the tag-based gain access to controls to Amazon Redshift consents. This service has actually enhanced the time to market for our information and supplies constant privileges throughout various business-driven classifications.
If you have any concerns or remarks, please leave them in the remarks area.
About the Authors
 Ashish Prabhu is a Senior Supervisor of Software Application Engineering in Morningstar, Inc. He concentrates on the solutioning and providing the various elements of Data Lake and Data Storage facility for Morningstar’s Business Data and Platform Group. In his extra time he takes pleasure in playing basketball, painting and spending quality time with his household.
Ashish Prabhu is a Senior Supervisor of Software Application Engineering in Morningstar, Inc. He concentrates on the solutioning and providing the various elements of Data Lake and Data Storage facility for Morningstar’s Business Data and Platform Group. In his extra time he takes pleasure in playing basketball, painting and spending quality time with his household.
 Stephen Johnston is a Distinguished Software Application Designer at Morningstar, Inc. His focus is on information lake and information warehousing innovations for Morningstar’s Business Data Platform group.
Stephen Johnston is a Distinguished Software Application Designer at Morningstar, Inc. His focus is on information lake and information warehousing innovations for Morningstar’s Business Data Platform group.
 Colin Ingarfield is a Lead Software Application Engineer at Morningstar, Inc. Based in Austin, Colin concentrates on gain access to control and information privileges on Morningstar’s growing Data Lake platform.
Colin Ingarfield is a Lead Software Application Engineer at Morningstar, Inc. Based in Austin, Colin concentrates on gain access to control and information privileges on Morningstar’s growing Data Lake platform.
 Don Drake is a Senior Analytics Professional Solutions Designer at AWS. Based in Chicago, Don assists Financial Solutions clients move work to AWS.
Don Drake is a Senior Analytics Professional Solutions Designer at AWS. Based in Chicago, Don assists Financial Solutions clients move work to AWS.