Complexion is an observable attribute that is subjective, viewed in a different way by people (e.g., depending upon their area or culture) and hence is made complex to annotate. That stated, the capability to dependably and properly annotate complexion is extremely essential in computer system vision. This emerged in 2018, when the Gender Tones research study highlighted that computer system vision systems had a hard time to spot individuals with darker complexion, and carried out especially improperly for females with darker complexion. The research study highlights the value for computer system scientists and professionals to assess their innovations throughout the complete series of complexion and at crossways of identities. Beyond assessing design efficiency on complexion, complexion annotations make it possible for scientists to step variety and representation in image retrieval systems, dataset collection, and image generation For all of these applications, a collection of significant and inclusive complexion annotations is crucial.
In 2015, in an action towards more inclusive computer system vision systems, Google’s Accountable AI and Human-Centered Innovation group in Research study partnered with Dr. Ellis Monk to freely launch the Monk Complexion (MST) Scale, a complexion scale that records a broad spectrum of complexion. In contrast to a market requirement scale like the Fitzpatrick Skin-Type Scale created for skin-related usage, the MST provides a more inclusive representation throughout the series of complexion and was created for a broad series of applications, consisting of computer system vision.
Today we’re revealing the Monk Complexion Examples (MST-E) dataset to assist professionals comprehend the MST scale and train their human annotators. This dataset has actually been made openly offered to make it possible for professionals all over to produce more constant, inclusive, and significant complexion annotations. Together with this dataset, we’re offering a set of suggestions, kept in mind listed below, around the MST scale and MST-E dataset so we can all produce items that work well for all complexion.
Because we introduced the MST, we have actually been utilizing it to enhance Google’s computer system vision systems to make fair image tools for everybody and to enhance representation of complexion in Browse Computer system vision scientists and professionals beyond Google, like the managers of MetaAI’s Table talks dataset, are acknowledging the worth of MST annotations to supply extra insight into variety and representation in datasets. Incorporation into commonly offered datasets like these are vital to provide everybody the capability to guarantee they are constructing more inclusive computer system vision innovations and can check the quality of their systems and items throughout a wide variety of complexion.
Our group has actually continued to perform research study to comprehend how we can continue to advance our understanding of complexion in computer system vision. Among our core locations of focus has actually been complexion annotation, the procedure by which human annotators are asked to examine pictures of individuals and pick the very best representation of their complexion. MST annotations make it possible for a much better understanding of the inclusiveness and representativeness of datasets throughout a wide variety of complexion, hence making it possible for scientists and professionals to assess quality and fairness of their datasets and designs. To much better comprehend the efficiency of MST annotations, we have actually asked ourselves the following concerns:.
- How do individuals consider complexion throughout geographical places?
- What does international agreement of complexion appear like?
- How do we efficiently annotate complexion for usage in inclusive artificial intelligence (ML)?
The MST-E dataset
The MST-E dataset includes 1,515 images and 31 videos of 19 topics covering the 10 point MST scale, where the topics and images were sourced through TONL, a stock photography business concentrating on variety. The 19 topics consist of people of various ethnic cultures and gender identities to assist human annotators decouple the principle of complexion from race. The main objective of this dataset is to make it possible for professionals to train their human annotators and test for constant complexion annotations throughout different environment capture conditions.
 |
| The MST-E image set includes 1,515 images and 31 videos including 19 designs taken under different lighting conditions and facial expressions. Images by TONL. Copyright TONL.CO 2022 ALL RIGHTS BOOKED. Utilized with consent. |
All pictures of a subject were gathered in a single day to lower variation of complexion due to seasonal or other temporal impacts. Each topic was photographed in different postures, facial expressions, and lighting conditions. In addition, Dr. Monk annotated each topic with a complexion label and after that chose a “golden” image for each topic that finest represents their complexion. In our research study we compare annotations made by human annotators to those made by Dr. Monk, a scholastic professional in social understanding and inequality.
Regards to usage
Each design picked as a subject supplied permission for their images and videos to be launched. TONL has actually permitted for these images to be launched as part of MST-E and utilized for research study or human-annotator-training functions just. The images are not to be utilized to train ML designs.
Obstacles with forming agreement of MST annotations
Although complexion is simple for an individual to see, it can be challenging to methodically annotate throughout several individuals due to problems with innovation and the intricacy of human social understanding.
On the technical side, things like the pixelation, lighting conditions of an image, or an individual’s display settings can impact how complexion appears on a screen. You may observe this yourself the next time you alter the screen setting while seeing a program. The color, saturation, and brightness might all impact how complexion is shown on a screen. Regardless of these obstacles, we discover that human annotators have the ability to discover to end up being invariant to lighting conditions of an image when annotating complexion.
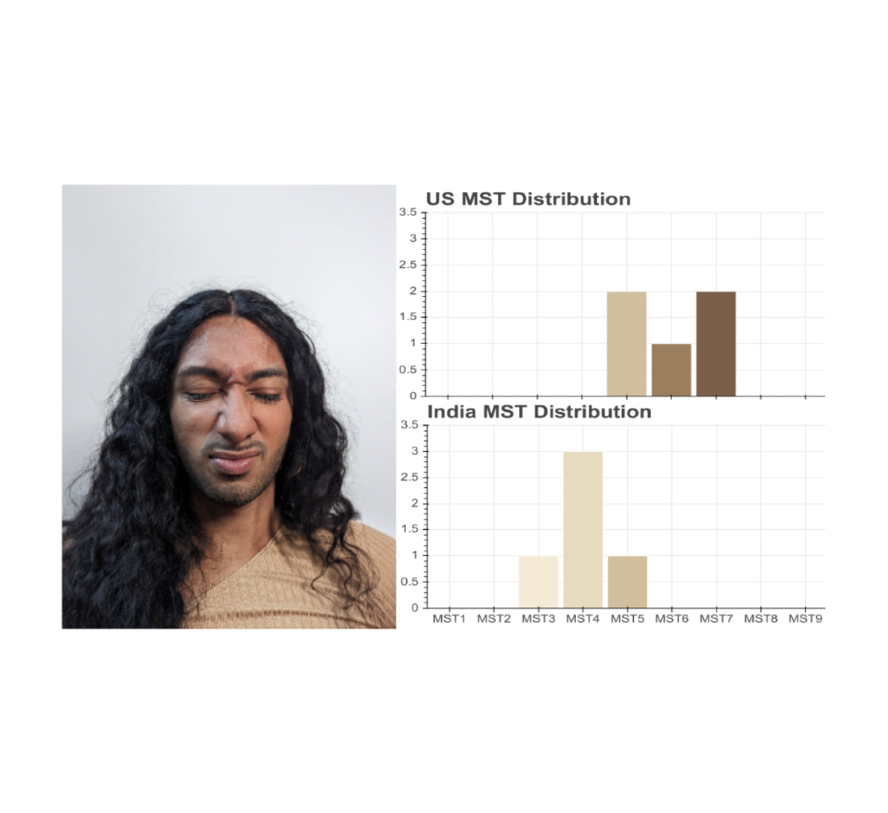
On the social understanding side, elements of an individual’s life like their area, culture, and lived experience might impact how they annotate different complexion. We discovered some proof for this when we asked professional photographers in the United States and professional photographers in India to annotate the very same image. The professional photographers in the United States saw this individual as someplace in between MST-5 & & MST-7. Nevertheless, the professional photographers in India saw this individual as someplace in between MST-3 & & MST-5.
 |
| The circulation of Monk Complexion Scale annotations for this image from a sample of 5 professional photographers in the U.S. and 5 professional photographers in India. |
Continuing this expedition, we asked skilled annotators from 5 various geographical areas (India, Philippines, Brazil, Hungary, and Ghana) to annotate complexion on the MST scale. Within each market each image had 5 annotators who were drawn from a wider swimming pool of annotators because area. For instance, we might have 20 annotators in a market, and choose 5 to examine a specific image.
With these annotations we discovered 2 essential information. Initially, annotators within an area had comparable levels of contract on a single image. Second, annotations in between areas were, typically, substantially various from each other. ( p<< 0.05). This recommends that individuals from the very same geographical area might have a comparable psychological design of complexion, however this psychological design is not universal.
Nevertheless, even with these local distinctions, we likewise discover that the agreement in between all 5 areas falls near to the MST worths provided by Dr. Monk. This recommends that a geographically varied group of annotators can get near to the MST worth annotated by an MST professional. In addition, after training, we discover no substantial distinction in between annotations on well-lit images, versus poorly-lit images, recommending that annotators can end up being invariant to various lighting conditions in an image– a non-trivial job for ML designs.
The MST-E dataset permits scientists to study annotator habits throughout curated subsets managing for possible confounders. We observed comparable local variation when annotating much bigger datasets with a lot more topics.
Complexion annotation suggestions
Our research study consists of 4 significant findings. Initially, annotators within a comparable geographical area have a constant and shared psychological design of complexion. Second, these psychological designs vary throughout various geographical areas. Third, the MST annotation agreement from a geographically varied set of annotators lines up with the annotations supplied by a specialist in social understanding and inequality. And 4th, annotators can discover to end up being invariant to lighting conditions when annotating MST.
Provided our research study findings, there are a couple of suggestions for complexion annotation when utilizing the MST.
- Having a geographically varied set of annotators is necessary to acquire precise, or near to ground fact, quotes of complexion.
- Train human annotators utilizing the MST-E dataset, which covers the whole MST spectrum and includes images in a range of lighting conditions. This will assist annotators end up being invariant to lighting conditions and value the subtlety and distinctions in between the MST points.
- Provided the wide variety of annotations we recommend having at least 2 annotators in a minimum of 5 various geographical areas (10 rankings per image).
Complexion annotation, like other subjective annotation jobs, is tough however possible. These kinds of annotations enable a more nuanced understanding of design efficiency, and eventually assist all of us to produce items that work well for every single individual throughout the broad and varied spectrum of complexion.
Recognitions
We want to thank our coworkers throughout Google dealing with fairness and addition in computer system vision for their contributions to this work, particularly Marco Andreetto, Parker Barnes, Ken Burke, Benoit Corda, Tulsee Doshi, Courtney Heldreth, Rachel Hornung, David Madras, Ellis Monk, Shrikanth Narayanan, Utsav Prabhu, Susanna Ricco, Sagar Savla, Alex Siegman, Komal Singh, Biao Wang, and Auriel Wright. We likewise want to thank Annie Jean-Baptiste, Florian Koenigsberger, Marc Repnyek, Maura O’Brien, and Dominique Mungin and the rest of the group who assist monitor, fund, and collaborate our information collection.